Features

Usability
SpikeCV provides a class SpikeStrem to encapsulate the spike data, normalized dataset interfaces with standard paramter passing modes, and a comprehensive modularization, making it easy for developers to customize and improve algorithms.

Real-time
For real-time data reading, SpikeCV has a multi-level thread for reading spike data at high temporal resolution based on multiple C++ thread pools. For real-time inference, The encapsulated SpikeStream instance can be supllied to multiple parallel threads of different models.

Spike Ecosystem
SpikeCV not only provides spike processing tools and spike-based visual algorithms but also provides spike camera hardware interfaces and normalized spike datasets. Beginners can thoroughly learn what spike data is and how to use spike cameras to tackle visual tasks.
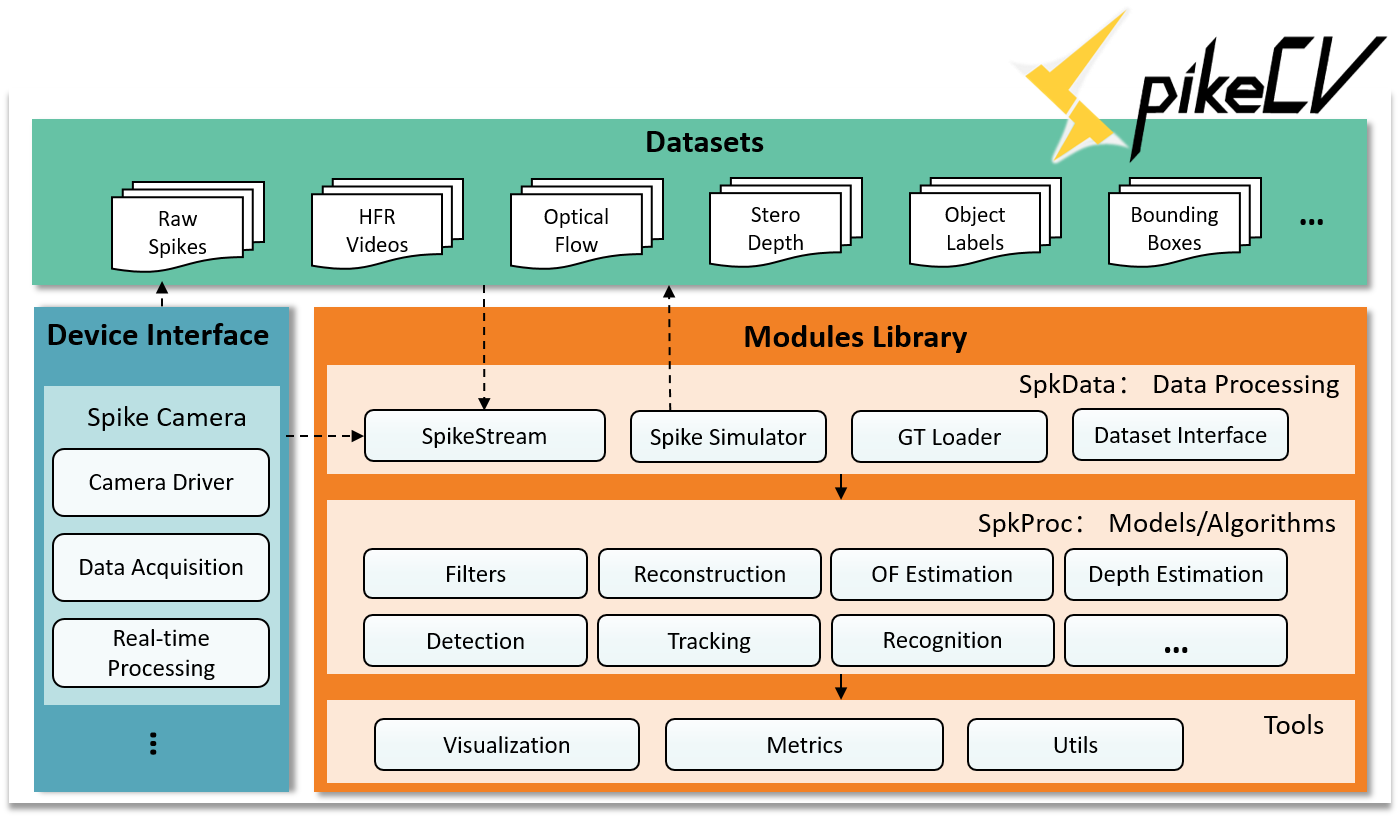
Architecture
- Dataset
Normalized datasets that can be used to validate or train intelligent models. The dataset files include the real scene generated by the spike camera or the spike simulator, and the corresponding label information such as video, optical flow, depth, and object category. We also provide supplementary configuration files for recording properties of spike data and label files. - Modules library
The module library includes three categories: data processing, vision model/algorithm, and tools. The data processing module SpkData includes the spike stream class, the spike simulator, the label loader, and the dataset interface for the training model. The algorithm library SpkProc contains various vision algorithms for spike cameras, and the Tool is a supporting development tool library responsible for visualization, metrics, and development utensils. - Device interface
The device interface is to facilitate the user to apply the spike-based algorithm to the realtime processing hardware. Currently, SpikeCV has integrated the spike camera. Users can use our spike camera interface to customize the scene to collect datasets or evaluate the real-time performance of the algorithm.
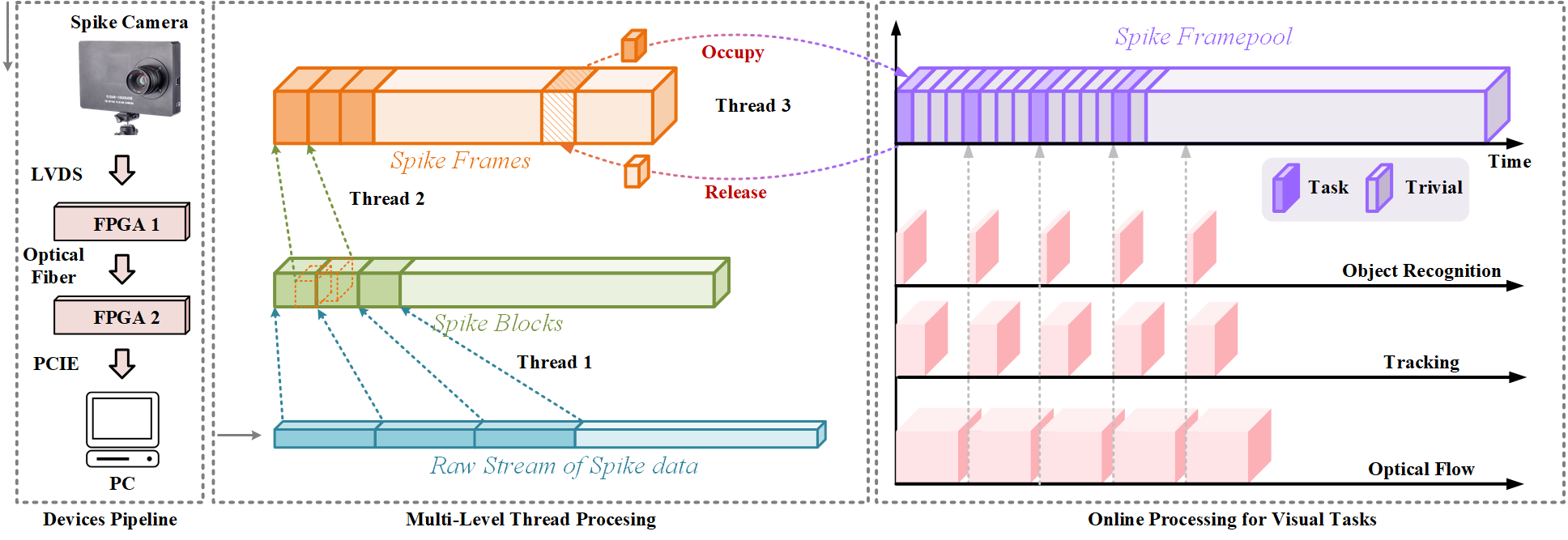
Real-Time Pipeline
We aim to synchronize the acquisition of data and the process of algorithms in a real-time scheme in the SpikeCV. The pipeline can parse user-friendly spikes from raw outputs of the hardware and process visual tasks in real time, consisting of two parts, multi-level threads for reading real-time spikes and online applications.
- Multi-level Threads Processing
Three threads are responsible for collecting spikes at different stages. Thread 1 takes the raw stream of spikes and packs them into blocks that are arranged into a queue LibBlockQueue. The blocks contain spikes and other information like frame headers. Thread 2 parses the spike blocks and assembles spikes into streams of bytes arranged in the spatial and temporal order. When the user enters a command to get camera data, these byte streams are continuously fetched and put into the queue Lib-FramePool. Thread 3 takes charge of handling spike frames between the C++ library and the user's APP in Python. The byte streams are converted to pieces of user-friendly frames. The APP also maintains a queue App-FramePool, and Thread 3 always delivers the data address from Lib-FramePool to App-FramePool. After occupying the data, App-FramePool will release the address back to Lib-FramePool. - Online visual applications
The second part is the mechanism of simultaneously processing multiple tasks cooperated with the App-FramePool in real-time. The main program always takes out frames from the App-FramePool. One frame will be processed when three threads are all in idle states, otherwise, its pointer will be released right back. In this way, algorithms for different tasks always process the same frame and the App-FramePool would not be blocked.