引言

易用性
SpikeCV 提供了 SpikeStream 类来封装脉冲数据,提供了标准化的数据集接口,以及标准的参数传递方式,还提供了全面的模块化,使得开发人员可以轻松定制和改进算法。

实时性
对于实时数据读取,SpikeCV 基于多个C++线程池使用多级线程来以高时间分辨率读取脉冲数据。对于实时推断,封装的SpikeStream实例可以供给多个不同模型的并行线程使用。

脉冲生态
SpikeCV 不仅提供了脉冲的处理工具和视觉算法,还提供了脉冲相机硬件接口和标准化的脉冲数据集。初学者可以全面学习什么是脉冲数据以及如何使用脉冲相机来处理视觉任务。
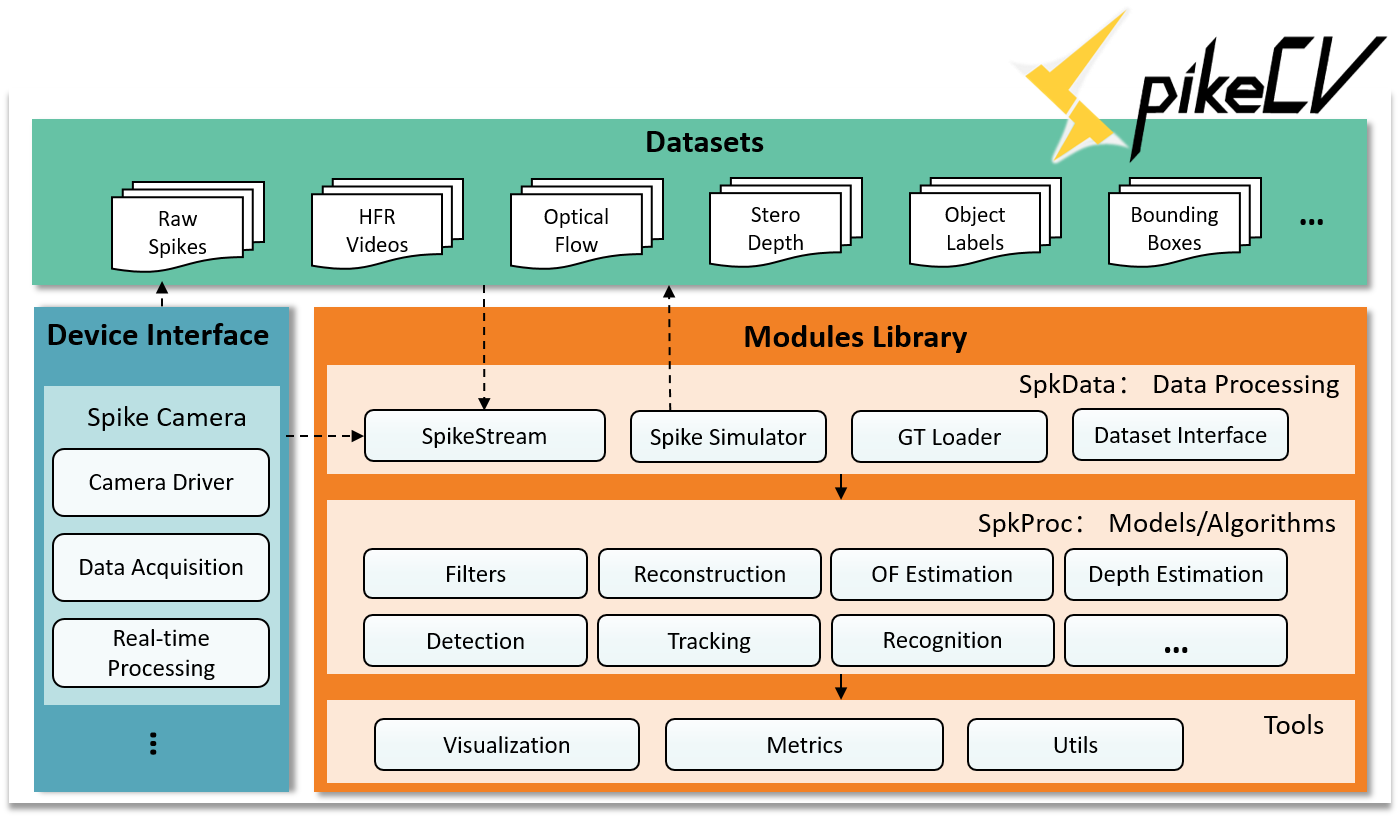
架构
- 数据集
SpikeCV提供了可用于验证或训练模型的标准化数据集。数据集文件包括由脉冲相机或脉冲模拟器生成的真实场景以及相应的标签信息,如视频、光流、深度和物体类别。我们还提供了用于记录脉冲数据和标签文件属性的附加配置文件 - 模块库
模块库包括三个类别:数据处理、视觉模型/算法和工具。数据处理模块 SpkData 包括脉冲流类、脉冲模拟器、标签加载器和用于训练模型的数据集接口。算法库 SpkProc 包含用于脉冲相机的各种视觉算法,而 Tool 是一个支持开发的工具库,负责可视化、度量和开发工具, metrics, and development utensils. - 硬件接口
硬件接口旨在帮助用户将基于脉冲的算法应用于实时处理硬件。目前,SpikeCV已经集成了脉冲相机的硬件接口。用户可以使用我们的脉冲相机接口来自己拍摄场景从而收集数据集或评估算法的实时性能
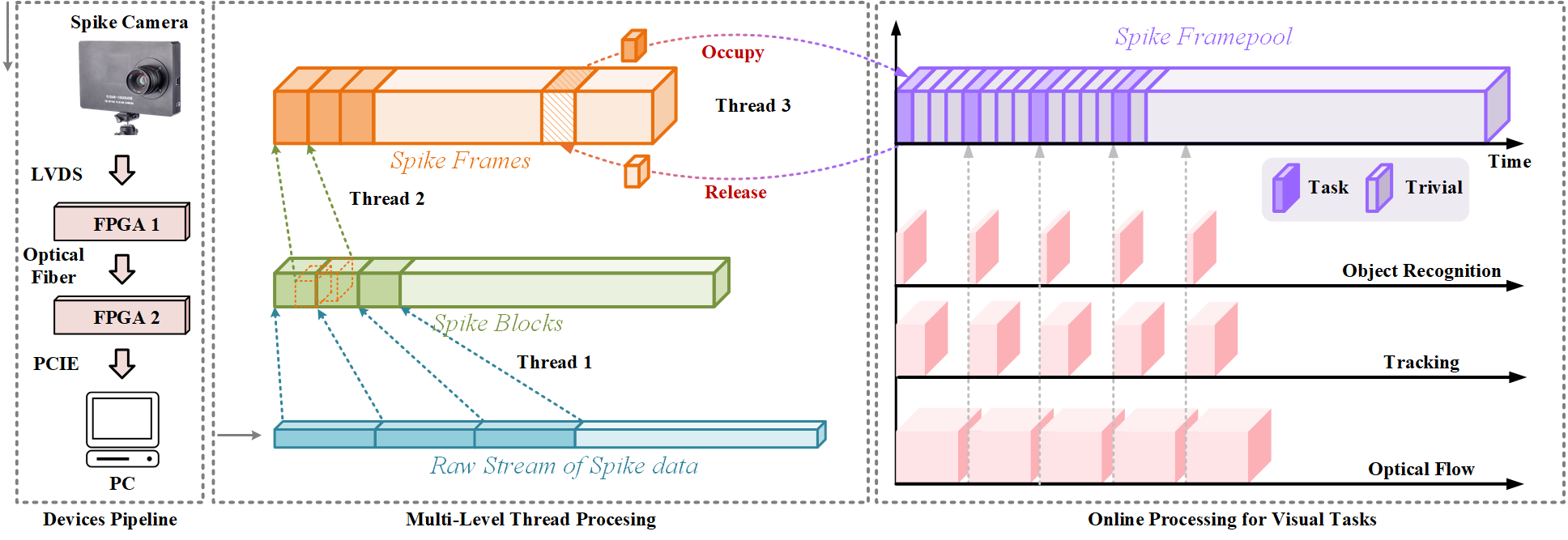
实时工作流程
我们的目标是在SpikeCV中实现数据获取和算法处理的实时方案。该流程可以从硬件的原始输出中解析用户友好的脉冲,并实时处理视觉任务。其包括两个部分:用于读取实时脉冲的多级线程和在线视觉应用。
- 多级线程
有三个线程负责在不同阶段收集脉冲。线程1获取脉冲的原始数据流,并将其打包成blocks,这些块按照一定的排列方式放入队列 LibBlockQueue 中。这些blocks包含脉冲以及帧头等其他信息。线程2解析脉冲blocks,将脉冲组装成按空间和时间顺序排列的字节流。当用户输入命令以获取相机数据时,这些字节流将不断被获取并放入队列 Lib-FramePool。线程3负责在C++库和用户的Python应用程序之间处理脉冲帧。字节流会被转换为用户友好的帧。应用程序还维护一个队列 App-FramePool,线程3会不断将数据地址从 Lib-FramePool 传递给 App-FramePool。在占用数据后,App-FramePool 会将地址释放回 Lib-FramePool。 - 在线视觉应用
第二部分是与 App-FramePool 协作的同时处理多个任务的实时机制。主程序总是从 App-FramePool 中取出帧。只有当三个线程都处于空闲状态时,才会处理一个帧,否则帧的指针会立即被释放回去。这样,不同任务的算法总是处理同一帧,而且 App-FramePool 不会被阻塞。